현재 POST는 아직 작성 중인 게시글입니다.
게시글이 길어져 우선 학습하고 있는 내용을 요약없이 미리 게재하여 놓았으니 참고바랍니다.
이 글의 핵심은 CHAPTER 5 Representational State Transfer (REST) 부분이니 참고하셔서 열람 바랍니다.
REST란?
REST 아키텍처 스타일은 로이 필딩의 박사 논문에서 처음 제안된 설계 방식입니다.
https://ics.uci.edu/~fielding/pubs/dissertation/top.htm
Architectural Styles and the Design of Network-based Software Architectures
UNIVERSITY OF CALIFORNIA, IRVINE Architectural Styles and the Design of Network-based Software Architectures DISSERTATION submitted in partial satisfaction of the requirements for the degree of DOCTOR OF PHILOSOPHY in Information and Computer Science by Ro
ics.uci.edu
이번 POST는 논문을 번역하고 분석하며 REST가 무엇인지 분석해보고자 합니다.
결론부터 말씀드리면 제가 분석한 내용으로는 REST API는 컴포넌트간의 상호작용을 어떻게 하는 것이 좋을 것인지를 알려주는 가이드 라인 같은 것입니다. 상호작용의 확장성, 인터페이스의 일반성, 구성 요소의 독립적인 배치 및 축소를 위한 중간 구성 요소 상호 작용 지연, 보안 강화, 레거시 시스템 캡슐화 등 또한, 소프트웨어와 네트워크의 접점을 탐구하고 네트워크 기반 소프트웨어를 이해하고 평가하는 것이 목표로 합니다.
논문 목차
- 1~3장은 아키텍처 스타일을 통해 소프트웨어 아키텍처를 이해하기 위한 프레임워크를 정의하고, 스타일이 네트워크 기반 응용 소프트웨어의 아키텍처 설계를 안내하는 데 어떻게 사용될 수 있는지 보여줍니다.
- 4 장에서는 웹 아키텍처의 요구사항, 해결해야할 문제를 설명하고 이를 해결하기 위한 접근 방법을 제시합니다.
- 5장에서는 REST 아키텍쳐에 대해서 설명하고 있으며 REST는 구성요소 상호작용, 인터페이스의 일반성, 구성요소의 독립적인 배치, 상호 작용 지연 시간을 줄이고 보안을 강화하기 위한 중간 구성 요소 및 레거시 시스템을 캡슐화 등을 강조합니다.
- 6장은 REST 아키텍쳐가 현대 웹의 표준으로 발전했다는 것을 보여줍니다.
CHAPTER 1 Software Architecture
기존 문헌에 있는 정의들을 검토하고, 네트워크 기반 응용 아키텍처에 대한 나의 통찰을 바탕으로 소프트웨어 아키텍처를 위한 자체 일관된 용어를 정의.
아래는 CHAPTER 1에 나오는 정의입니다.
자세한 설명은 논문에 적혀 있으니 관심 있으신 분들은 한번 읽어보시길 추천 드립니다.
1.1 Run-time Abstraction
"A software architecture is an abstraction of the run-time elements of a software system during some phase of its operation. A system may be composed of many levels of abstraction and many phases of operation, each with its own software architecture."
"소프트웨어 아키텍처는 소프트웨어 시스템의 운영 중 특정 단계에서의 런타임 요소들에 대한 추상화입니다. 시스템은 다양한 추상화 수준과 다양한 운영 단계를 가질 수 있으며, 각각은 자체적인 소프트웨어 아키텍처를 가지고 있습니다."
1.2 Elements
"A software architecture is defined by a configuration of architectural elements—components, connectors, and data—constrained in their relationships in order to achieve a desired set of architectural properties."
"소프트웨어 아키텍처는 구성 요소, 커넥터, 데이터와 같은 아키텍처 요소들의 구성에 의해 정의됩니다. 이들은 원하는 아키텍처 속성을 달성하기 위해 그들의 관계에서 제약을 받습니다."
1.2.1 Components
"A component is an abstract unit of software instructions and internal state that provides a transformation of data via its interface."
"구성 요소는 소프트웨어 명령과 내부 상태의 추상적 단위로, 그 인터페이스를 통해 데이터의 변환을 제공합니다.
1.2.2 Connectors
"A connector is an abstract mechanism that mediates communication, coordination, or cooperation among components."
"커넥터는 구성 요소들 간의 통신, 조정 또는 협력을 매개하는 추상적 메커니즘입니다."
1.2.3 Data
"A datum is an element of information that is transferred from a component, or received by a component, via a connector"
"데이터는 컴포넌트로부터 전송되거나, 컴포넌트에 의해 수신되는 정보의 요소로, 커넥터를 통해 이루어집니다."
1.3 Configuration
"A configuration is the structure of architectural relationships among components, connectors, and data during a period of system run-time"
"구성은 시스템 런타임 동안 구성 요소, 커넥터 및 데이터 간의 아키텍처 관계의 구조를 의미합니다."
1.4 Properties
"소프트웨어 아키텍처의 아키텍처 속성 집합에는 시스템 내에서 구성 요소, 커넥터 및 데이터의 선택과 배열에서 파생되는 모든 속성이 포함됩니다"
1.5 Styles
"아키텍처 스타일은 아키텍처 요소의 역할이나 특성에 제한을 두고, 해당 스타일에 부합하는 아키텍처 내에서 그 요소들 간의 허용되는 관계를 제한하는 일련의 아키텍처 제약들로 이루어진 조정된 집합입니다. 이는 아키텍처 설계에서 특정한 패턴이나 규칙을 적용하는 것을 의미하며, 이를 통해 일관된 아키텍처 특성과 행동을 유도합니다."
"An architectural style is a coordinated set of architectural constraints that restricts the roles/features of architectural elements and the allowed relationships among those elements within any architecture that conforms to that style."
1.6 Patterns and Pattern Languages
이 내용은 아키텍처 스타일과 객체지향 프로그래밍 커뮤니티의 디자인 패턴 및 패턴 언어 사용에 대해 다루며, 알렉산더의 디자인 철학을 기반으로 소프트웨어 아키텍처의 다양한 측면을 탐구합니다.
1.7 Views
아키텍처 관점은 응용 프로그램 및 도메인별로 다르며, 다양한 이슈를 다루고, Perry와 Wolf가 제시한 처리, 데이터, 연결 관점을 포함해 여러 관점에서 아키텍처를 볼 수 있다는 내용입니다.
1.8 Related Work
이 섹션에서는 소프트웨어 아키텍처 연구의 다양한 분야를 탐구합니다. 디자인 방법론, 디자인 패턴 및 패턴 언어, 참조 모델 및 도메인별 소프트웨어 아키텍처, 아키텍처 설명 언어, 그리고 형식적인 아키텍처 모델에 대한 연구가 포함됩니다. 각각의 분야는 소프트웨어 아키텍처를 이해하고 구축하는 다양한 접근 방식을 제시하며, 특정 아키텍처 스타일이나 패턴에 맞는 도구와 기술을 제공합니다.
1.8.1 Design Methodologies
1.8.2 Handbooks for Design, Design Patterns, and Pattern Languages
1.8.3 Reference Models and Domain-specific Software Architectures (DSSA)
1.8.4 Architecture Description Languages (ADL)
1.8.5 Formal Architectural Models
CHAPTER 2 Network-based Application Architectures
이 장에서는 네트워크 기반 응용 아키텍처에 초점을 맞추고 이러한 아키텍처의 설계를 안내하는 데 스타일이 어떻게 사용될 수 있는지에 대해 말해줍니다.
2.1 Scope
해당 논문은 아키텍처 스타일의 범위를 네트워크 기반 애플링케이션으로 한정하여 설명합니다.
2.1.1 Network-based vs. Distributed
네트워크 기반 아키텍처와 일반 소프트웨어 아키텍처의 차이는 구성 요소 간 통신이 메시지 전달로 제한되며, 이 논문은 사용자의 투명성을 보존하는 스타일에 국한되지 않고 네트워크 기반 시스템을 다룹니다.
2.1.2 Application Software vs. Networking Software
이 논문은 사용자 작업의 목표를 기능적 아키텍처 속성으로 표현할 수 있는 응용 소프트웨어 아키텍처에 초점을 맞추며, 운영 체제와 네트워킹 소프트웨어를 제외합니다.
2.2 Evaluating the Design of Application Architectures
주어진 응용 프로그램 도메인에 가장 적합한 아키텍처를 선택하고 만드는 데 초점을 맞추고 있으며, 아키텍처 설계의 평가를 위해 디자인의 제약을 분석하고, 그 제약에 의해 생성된 속성을 응용 프로그램의 목표와 비교하는 방법을 제시
2.3 Architectural Properties of Key Interest
이 부분은 논문에서 아키텍처 스타일을 구분하는데 사용되는 주요 아키텍처 속성들을 설명하며, 이들은 조사된 제한된 스타일 세트에 의해 영향을 받는 속성들에 초점을 맞추고 있습니다.
2.3.1 Performance
네트워크 기반 응용 프로그램의 성능을 다루며, 아키텍처 스타일이 사용자 인식 성능, 네트워크 성능 및 효율성에 미치는 영향을 분석합니다.
2.3.2 Scalability
많은 구성 요소나 상호 작용을 효과적으로 처리하는 아키텍처의 능력을 나타내며, 구성 요소 간의 결합, 상호 작용 빈도 및 처리 방식에 의해 영향을 받습니다.
2.3.3 Simplicity
2.3.4 Modifiability
2.3.5 Visibility
2.3.6 Portability
2.3.7 Reliability
CHAPTER 3 Network-based Architectural Styles
3.4 Hierarchical Styles
3.4.1 Client-Server (CS)
Client-Server 스타일은 네트워크 기반 애플리케이션에서 자주 볼 수 있는 아키텍쳐 스타일입니다.
- Client: 서버에 요청을 보냄 (트리거)
- Server: 서비스를 제공 (반응)
이 스타일의 핵심은 관심사 분리이며, 서버 컴포넌트를 단순화하여 확장성을 향상시키는데이 있습니다.
클라이언트와 서버 간읜 애플리케이션 상태 분할을 제한하지 않으며, 종종 커넥터 구현에 사용되는 매커니즘으로 언급
즉, 서버와 클라이언트 간의 기능 분리를 통해 확장성을 개선하고 컴포넌트의 독립적인 진화를 가능하게 함
3.4.2 Layered System (LS) and Layered-Client-Server (LCS)
Layered System (LS)은 계층적으로 구성되어 각 계층이 그 위의 계층에 서비스를 제공하고 아래 계층의 서비스를 사용합니다.
Layered System (LS) 는 순수 스타일로 간주 되지만 네트워크 기반 시스템에서는 Layered-Client-Server (LCS) 로 사용됩니다.
Layered System은 여러 계층간의 결합을 감소시키고, 내부 계층은 외부 계층의 인접한 부분만 볼수 있게 하여 외부 층을 제외한 모든 층에서 진화성과 재사용성을 향상시킵니다.
- 장점: Layered-Client-Server은 프록시와 게이트웨이 컴포넌트를 추가하여 시스템에 로드 밸런싱 및 보안 검사와 같은 기능을 추가할 수 있습니다.
- 단점: 데이터 처리에 오버헤드와 대기 시간을 추가하여 사용자가 인식하는 성능을 감소 시킵니다.
프록시: 하나 이상의 클라이언트 구성 요소에 대한 공유 서버로서, 요청을 받아 이를 서버 구성 요소로 전달하며, 필요한 경우 번역합니다.
게이트웨이: 서비스를 요청하는 클라이언트 또는 프록시에게는 일반 서버처럼 보이지만 실제로는 그 요청을 내부 계층의 서버로 전달합니다.
LCS는 대용량 분산 시스템의 해결책이기도 하고 드물게 서버를 계층으로 구성하여 서비스를 클라이언트가 직접 처리하는 대신 중재자로써 사용되기도 합니다.
3.4.3 Client-Stateless-Server (CSS)
Clent-Server에서 파생된 스타일로써, 서버 컴포넌트에서 세션 상태를 허용하지 않는 것입니다.
따라서, 클라이언트에서 서버로의 각 요청을 이해하는 데 필요한 모든 정보를 포함해야 하며 서버에 저장된 컨텍스트를 활용할 수 없습니다.
세션 상태는 전적으로 클라이언트에 유지됩니다.
이러한 스타일은 가시성, 신뢰성, 확장성을 향상시키지만 반복되는 데이터(상호작용당 오버헤드)를 증가시켜 네트워크 성능을 저하 시킬 수 있습니다.
3.4.4 Client-Cache-Stateless-Server (C$SS)
Client-Stateless-Server에 cache가 추가된 스타일입니다.
캐시는 중재자 역할을 하며, 이전 요청에 대한 응답이 캐시 가능하다고 간주되면 나중에 동일하거나 서버로 전달될 경우 캐시에 있는 응답을 재사용 할 수 있습니다.
이를 통해 상호작용을 줄이고 효율성 및 사용자 경험을 개선합니다.
3.5 Mobile Code Styles
3.5.3 Code on Demand (COD)
Code on Demand 스타일은 클라이언트 컴포넌트는 자원에 접근할 수 있지만 처리 방법은 알지 못합니다.
클라이언트는 원격 서버에 방법을 나타내는 코드를 요청하고 코드를 받아 로컬에서 실행합니다.
Code on Demand의 장점은 클라이언트에 새로운 기능을 추가할 수 있게 하는 것입니다.
이는 확장성 및 구성 가능성을 향상시키고, 클라이언트의 환경에 맞게 실행 될 수 있도록 조정하고 사용자와의 직접적인 상호작용을 통해, 원격 처리하는 것보다 더 나은 경험을 제공합니다.
실행 환경 관리의 필요성으로 인해 단숭함은 감소하지만 서버의 확장성이 향상되고, 서버 자원을 소모했을 작업을 클라이언트로 오프로드 할 수 있습니다.
가장 큰 단점은 서버가 단순한 데이터 대신 코드를 전송함으로 가시성이 떨어진 다는 것이고 클라이언트가 서버를 신뢰할 수 없는 경우 배포 문제로까지 이어집니다.
CHAPTER 5 Representational State Transfer (REST)
이 장에서는 분산 하퍼미디어 시스템을 위한 Representational State Transfer (REST) 아키텍처 스타일을 소개하고 자세히 설명합니다. REST는 소프트웨어 공학 원칙을 안내하고 이러한 원칙을 유지하기 위해 선택된 상호작용 제약을 다루며, 다른 아키텍처 스타일의 제약과 비교합니다. REST는 3장에서 설명된 여러 네트워크 기반 아키텍처 스타일에서 파생되었으며, 균일한 커넥터 인터페이스를 정의하는 추가적인 제약과 결합되었습니다. 1장의 소프트웨어 아키텍처 프레임워크를 사용하여 REST의 아키텍처 요소를 정의하고 전형적인 아키텍처의 프로세스, 커넥터, 데이터 뷰를 검토합니다.
5.1 Deriving REST
웹 아키텍쳐의 설계 근거는 아키텍쳐내의 제약이 적용된 요소들의 집합으로 이루어진 아키텍쳐 스타일로 설명이 된다.
진화하는 스타일에 제약을 추가함으로써 미치는 영향을 검토하면서 제약조건에 의해 요도되는 속성들을 식별할 수 있습니다.
즉 이번 섹션에서는 REST 아키텍처 스타일을 유도하는 과정을 통해 REST에 대한 개요를 제공하고, 추후 섹션에서 REST 스타일을 구성하는 구체적인 제약을 자세히 다룹니다.
5.1.1 Starting with the Null Style
이 부분에서는 아키텍처 설계 과정의 두 가지 접근 방식을 소개하며, REST가 두 번째 접근 방식, 즉 점진적으로 제약을 식별하고 적용하는 방식을 통해 개발되었음을 설명합니다. Null 스타일은 제약이 없는 아키텍처의 시작점으로, 구성 요소 간에 명확한 경계가 없는 시스템을 나타냅니다.이 논문에서는 Null Style에서 제약 조건을 추가하면서 REST를 설명합니다.

5.1.2 Client-Server
첫 번째로 추가된 제약은 Client-Server 아키텍쳐 스탈입니다.
Client-Server 제약의 원칙은 관심사 분리입니다.
데이터 저장의 관심사와 사용자 인터페이스에 대한 관심사를 분리함으로써, 사용자의 인터페이스 이식성과 서버의 확장성을 향상시킵니다. 이 분리는 구성 요소의 독립적인 진화를 가능하게 하여 다양한 조직 도메인에서의 웹의 발전을 지원합니다.

5.1.3 Stateless
3.4.3 Client-Stateless-Server (CSS) 스타일에 반복되는 내용으로써, 클라이언트와 서버 간의 통신은 본질적으로 무상태여야 합니다. 이는 클라이언트에서 서버로의 각 요청을 이해하는데 필요한 모든 정보를 포함해야 하며, 서버에 저장된 컨택스트를 이용할 수 없다는 것을 의미합니다.
따라서, 세션 상태는 전적으로 클라이언트에 유지됩니다. 이 제약은 가시성, 신뢰성, 확장성이라는 속성을 유도합니다.
1) 가시성(Visibility): 모니터링 시스템이 전체적인 요청을 파악하기 위해 단일 요청 넘어서의 것을 볼 파악할 필요가 없습니다.
2) 신뢰성(Reliability): 부분적인 실패를 복구하는 작업에 용이합니다.
3) 확장성(Scalability): 요청 간의 상태를 저장할 필요가 없기 때문에, 서버 자원을 빠르게 해제할 수 있고, 요청에 대한 정보를 관리할 필요가 없기 때문에 규현이 단순해 집니다.
그러나 Stateless 제약조건에는 Trade-off가 존재, 서버측에 요청에 대한 정보가 저장되지 않기 때문에, 반복되는 일련의 요청이 발생하여 네트워크 성능 저하와 클라이언트 의존도(서버측의 일관된 제어를 받을 수 없음)가 증가합니다.

5.1.4 Cache
네트워크 효율성을 향상시키기 위해 3.4.4 Client-Cache-Stateless-Server (C$SS)를 사용합니다.
케시 제약은 요청에 대한 응답 내의 데이터가 캐시 가능하거나 캐시 불가능하다는 것을 암시적 또는 명식적으로 표시해야합니다. 응답이 캐시가능한 경우는 동일한 요청에 대한 응답데이터를 재사용할 수 있는 권한을 부여합니다.
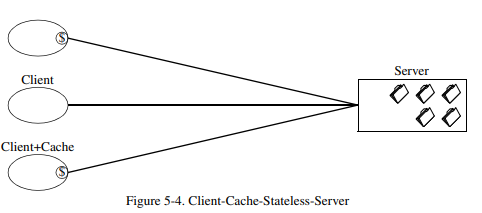
캐시 제약을 추가하면 통신 지연시간을 감소시켜 네트워크 효율성(efficiency), 확장성(scalability), 사용자 만족도(userperceived performance)를 향상시킬 수 있습니다. 그러나 trade-off로, 캐시가 만약 서버에 직접 요청했을 경우 얻었을 데이터와 상당히 다른 오래된 데이터를 포함하고 있다면 신뢰성을 감소시킬 수 있습니다.
아래 그림에서 묘사되어 있듯이, 초기 웹 아키텍쳐는 Client-Cache-Stateless-Server 제약조건들로 구성되어 있었습니다.

초기 설계도 stateless한 상호작용에 초점을 두었지만, 모든 리소스에 대해 일관적인 인터페이스로 제공되지는 않았습니다.그러나, 현재는 초기의 웹 아키텍쳐를 넘어섰습니다. 정적 문서 외에도, 이미지 맵 [Kevin Hughes] 및 서버 측 스크립트 [Rob McCool]와 같이 동적으로 응답을 생성하는 서비스를 식별할 수 있습니다. 프록시 및 공유 캐시 형태의 중개 컴포넌트에 대한 작업도 시작되었지만, 이들이 신뢰성 있게 통신하기 위해서는 프로토콜의 확장이 필요했습니다.
5.1.5 Uniform Interface
REST 아키텍처 스타일의 핵심적인 특징은 컴포넌트간의 unniform interface입니다.
컴포넌트 인터페이스에 일반성(generality)를 적용함으로써, 저체적인 시스템 아키텍처는 단순화되고 상호작용은의 가시성(visibility)은 향상됩니다.
이로 인해 각 컴포넌트들은 독립적으로 발전할 수 있는 진화 가능성을 가지게 됩니다. 그러나, uuniform interface으로 인해 효율성(efficiency)은 저하됩니다. 특정 애플리케이션의 필요에 특정한 것이 아닌 표준화 형태로 변환되어야 하기 때문입니다. Rest 인터페이스는 웹에서 대규모 하이퍼미디어 데이터 전송을 효과적으로 하기 위해 설계되었습니다.

REST는 4가지 제약조건에 의해 정의됩니다. (5.2에서 설명)
1. identification of resources
2. manipulation of resources through representations
3. self-descriptive messages
4. hypermedia as the engine of application state
5.1.6 Layered System
Internet-scale에서의 요구사항을 개선하기 위해 Layered System 제약조건을 추가합니다.
Layered System 스타일은 컴포넌트간의 인접하고 있는 계층 이상을 볼 수 없도록 제한함으로써, 전체 시스템의 복잡도를 제한하고 구조의 독립성을 증가십니다. (핵심)
계층구조는 레거시 서비스를 캡슐화하고, 레거시 클라이언트로부터 새로운 서비스를 보호하는 데 사용될 수 있습니다. 간혹 공유 중개 컴포넌트로 사용함으로써 컴포넌트를 단순화하고 여러 네트워크, 프로세서 사이에서 서비스의 로드밸런싱을 가능하게 하며, 시스템의 확장성을 향상시킬 수 있습니다. 그러나 단점으로는 데이터 처리에 오버헤드와 지연이 삼화되어 사용자가 인지하는 성능이 감소합니다. 단, 캐시 제약을 지원하는 네트워크 기반 시스템에서 중개 컴포넌트에 공유 캐시를 둠으로써 상쇄할 수 있습니다.
REST에서는 메시지가 자기 서술적(self-discriptive)이며, 메시지 자체만으로 그 의미를 파악할 수 있기 때문에, 데이터를 효과적으로 전송할 수 있게 되는 것이다. 이러한 계층은 조직 경계에서 보안 정책을 집행할 수 있으며, 균일한 인터페이스 제약과 결합하여 하이퍼미디어 상호작용의 대규모 데이터 흐름을 효과적으로 처리할 수 있는 아키텍처 속성을 유도합니다.

5.1.7 Code-On-Demand
REST의 마지막 제약조건은 Code on Demand 입니다.
REST는 애플릿 또는 스크립트 형태로 코드를 다운로드하여 실행할 수 있게 함으로써 클라이언트 기능을 확장할 수 있습니다. 이는 사전에 구현해야 할 기능의 수를 줄여 클라이언트를 단순화 합니다. 배포 후 기능을 다운로드할 수 있게 함으로써 시스템의 확장성을 개선합니다. 그러나 가시성을 감소시킵니다. 따라서 이 제약조건은 선택적인 제약조건입니다. 선택적 제약조건이 모순처럼 보일 수 있지만 아키텍쳐가 전체 시스템의 어떤 영역에서 선택적 제약이 적용되는 부분에만 해당 제약의 이점이 있다는 것을 의미합니다.

5.1.8 Style Derivation Summary

5.2 REST Architectural Elements
REST 아키텍처 스타일은 분산 하이퍼미디어 시스템 내의 아키텍쳐 요소를 추상화한 것입니다.
REST는 컴포넌트 구현의 세부적인 것에 초점을 두는 것이 아니라 아래와 같은 3가지 컴포넌트의 역할에 초점을 둡니다.1) Component: 구성 요소
2) Connector: 구성 요소와의 상호작용에 대한 제약
3) Data: 데이터 요소의 해석
5.2.1 Data Elements
분산 객체 스타일은 모든 데이터가 처리 컴포넌트 내에 캡슐화되고 숨겨지는 반면, REST에서는 데이터 요소가 특성과 상태를 가집니다. (이것이 REST의 key aspect)
이 설계의 근거는 분산 하이퍼미디어의 특성에서 찾을 수 있습니다. 링크가 선택되면, 정보는 저장되어 있는위치에서 이동해야 합니다. 이러한 특성은 processing agent"(e.g., mobile code, stored procedure, search expression)를 데이터로 이동시키는 것이 가능합니다.
분산 하이퍼미디어 설계할 때에는 다음의 세 가지 기본적인 옵션을 가집니다.
Option 1) 데이터를 위치한 곳에서 랜더링하고 고정된 형태의 이미지로 수신자에게 전송
Option 2) 데이터를 렌더링 엔진과 함께 캡슐하하여 둘 다 수신자에게 전송
Option 3) 원시 데이터 유형을 알 수 있도록 하는 메타데이터와 함께 데이터 원본을 전송하여 수신자가 렌더링 엔진을 선택할 수 있도록 하는 방법
각 옵션은 장/단점을 가지고 있습니다.
Option 1.
전통적인 Client-Server 스타일은 데이터의 진짜 성질에 대한 정보를 발신자 내부에 숨겨 데이터 구조에 대한 추정이 필요없고, 클라이언트 구현을 더욱 쉽게 합니다. 그러나, 수신자의 기능을 제한하고 부하의 대부분을 발신자에 두어 확장성 문제를 초래합니다.
Option 2.
mobile object 스타일은 데이터를 고유한 렌더링 엔진과 함께 캡슐화함으로써 정보 은닉을 제공하며, 데이터에 대한 특수 처리를 가능하게 하는 장점이 있습니다. 그러나, 이는 수신자의 기능을 그 엔진 내에서 예상되는 범위로 제한하고, 전송되는 데이터의 양을 크게 증가시킬 수 있는 단점도 있습니다.
Option 3.
발신자를 단순하고 확장 가능하게 유지하면서 전송되는 바이트 수를 최소화하지만 정보 은닉의 이점을 잃고 발신자와 수신자가 동일한 데이터 유형을 처리해야합니다.
REST는 데이터 타입과 메타데이터에 대한 공유 이해에 초점을 두고, 표준화된 인터페이스를 이용하여 공개되는 범위를 제한함으로 세가지 옵션을 하이브리드하게 제공합니다. REST는 클라이언트-서버 스타일의 관심사 분리를 달성하고 서버의 확장성 문제 없이, 일반적인 인터페이스를 통한 정보 은닉을 허용하며, 다운로드 가능한 기능 엔진을 통해 다양한 기능 세트를 제공합니다.
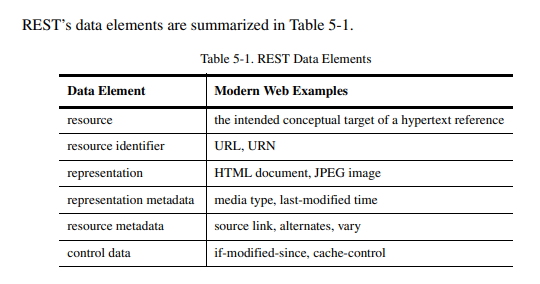
5.2.1.1 Resources and Resource Identifiers
REST의에서 정보의 핵심 추상화는 리소스입니다.
이름을 가진 어떠한 정보도 리소스가 될 수 있습니다. (a document or image, a temporal service (e.g. "today's weather in Los Angeles"), a collection of other resources, a non-virtual object (e.g. a person)) 하이퍼 텍스트 참조 대상이 될 수 있는 모든 개념은 리소스 정의에 맞아야합니다.
리소스는 특정 시점에서 엔티티가 아닌 엔티티의 집합과 매핑된 개념입니다.
더 정확히 말하자면, 리소스 R은 시간 t에 대해 동등한 엔티티나 값의 집합에 매핑되며, 시간에 따라 변화하는 맴버집 함수 MR(t)입니다. 이떄, 집합의 값은 resource representation 또는 resource identifier일 수 있습니다. 리소스는 개념이 실현되기 전에 그 개념에 대한 참조를 허용하는 빈 집합에 매핑 될 수 있습니다. 이 개념은 하이퍼텍스트 시스템에 생소한 개념입니다. 해당 리소스가 시간에 따라 변화하는 것인지 변하지 않는 것인지를 구분되어야 한다는 의미입니다. 예를 들어 논문의 버전은 시간에 따라 변화할 수 있는 값이며 X 컨퍼런스에 개제된 논문은 정적입니다.
이 추상적인 리소스 정의는 웹 아키텍처의 핵심 기능을 가능하게 합니다.
첫째) 다양한 정보를 타입이나 구현으로 인위적으로 구분하지 않고 포괄함으로써 일반성을 제공합니다.
둘째) 참조 표현을 늦게 바인딩 할 수 있게 하여, 요청의 특성에 따라 content negotiation을 가능하게 합니다.
셋째) 작성자가 특정 개념의 단일 표현이 아닌 개념 자체를 함조할 수 있게 함으로써, 표현이 변경될 때마다 모든 기존 링크를 변경할 필요가 없어집니다.
REST는 resource identifier를 사용하여 컴포넌트간의 상호작용에 관련되 특정 리소스를 식별합니다.
REST Connector는 membership function가 어떻게 정의되었는지 또는 요청을 처리하는 소프트웨어의 유형에 관계없이 리소스의 값 집합에 접근하고 조작하는 일반적인 인터페이스를 제공합니다. 리소스 식별자를 할당한 명명 권한은 시간이 지나도 매핑의 의미론적 유효성을 유지할 책임이 있습니다.
REST는 식별자를 정의할 떄, 식별하고자 하는 개념의 특성에 적합하도록 작성함으로써 리소스 식별자만으로 해당 리소스를 식별할 수 있도록 합니다.
전통적인 하이퍼텍스트 시스템은 정보가 변경될 때마다 변경되는 고유한 노드 또는 문서 식별자를 사용하며, 웹의 광대한 규모와 다기관 도메인 요구사항에는 중앙 집중식 링크 서버가 적합하지 않으므로,
REST는 대신 작성자가 식별하려는 개념의 성격에 가장 잘 맞는 리소스 식별자를 선택하도록 의존합니다.
5.2.1.2 Representations
REST의 구성 요소는 리소스의 상태(status)를 파악하고 representation을 사용하여 리소스에 대한 작업을 수행하고 컴포넌트 간에 전송합니다. representation은 바이트의 연속이며, 이러한 바이트를 설명하기위한 메타데이터로 구성되어 있습니다. 많이 사용되지만 정확하지 않은 표현: document, file, and HTTP message entity, instance, or variant
representation은 데이터, 데이터를 설명하는 메타데이터, 메타데이터를 설명하는 메타데이터로 구성되어 있습니다. 메타데이터는 key-value 형태이며, key는 값의 구조와 의미를 정의하는 표준에 해당합니다. 응답메세지에는 representation 메타데이터, resource 메타데이터 모두 포함 가능합니다.
Control Data는 요청되는 작업이나 의미와 같은 컴포넌트 간에 메시지하는 것이 목적입니다. message control data에 따라 요청된 리소스의 상태나 리소스의 값을 나타내는 표현 형태를 결정합니다. 이를 통해 리소스의 원격 작성이 가능하며, 리소스의 다양한 표현 중에서 최적의 표현을 선택하기 위해 content negotiation이 사용될 수 있습니다.
representation의 데이터 타입은 media type이라고 합니다. 메시지에 representation을 포함시키면, 해당 메시지 내의 control data, 미디어 타입에 따라 수신자는 representation을 처리할 수 있습니다. 복합 미디어 타입을 통해 하나의 메시지 안에 여러 표현을 포함시킬 수 있습니다.
미디어 타입의 설계는 분산 하이퍼미디어 시스템에서 사용자가 인지하는 성능에 중요한 영향을 미칩니다. 랜더링 정보를 어떻게 배치하느냐에 따라서 사용자의 인지 성능에 차이가 있기 때문에 중요한 랜더링 정보를 앞에 배치하는 등의 방법으로 사용자에게 인지 성능을 개선할 수 있습니다.
5.2.2 Connectors
5.2.3 Components
5.3 REST Architectural Views2024-03-12 ㅇ
5.3.1 Process View
5.3.2 Connector View
5.3.3 Data View
5.4 Related Work
'프로그래밍 > IT' 카테고리의 다른 글
| JWT (JSON Web Tokens) 란? (0) | 2024.02.22 |
|---|---|
| Git 정리 (0) | 2022.11.13 |
| 데이터베이스 요약 (0) | 2021.04.19 |
| JAVA 프로그래밍 요약 (0) | 2021.04.19 |
| 가비지컬렉션 (0) | 2020.04.29 |

